TensorFlow的设计思路浅析
问:为什么要了解深度学习框架相关的内容?
目前的大规模深度学习网络往往在异构智能计算系统上运行。
现今采用异构智能计算系统的主要原因:
近十年来通用 CPU 的计算能力增长近乎停滞,而智能计算能力的需求在不断以指数增长,二者形成了剪刀差。例如,寒武纪深度学习处理器能够以比通用 CPU 低一个数量级的能耗,达到 100 倍以上的处理速度。
现阶段的智能计算系统通常是集成CPU和智能芯片的异构系统,软件上通常包括一套面向开发者的智能计算编程环境(包括编程框架和编程语言)。
——《智能计算系统》
目前常用的深度学习编程框架包括 TensorFlow 和 MXNet 等,常用的深度学习编程语言包括 CUDA 语言和 BCL 语言等。 因此,异构系统在提高性能的同时,也带来了编程上的困难。
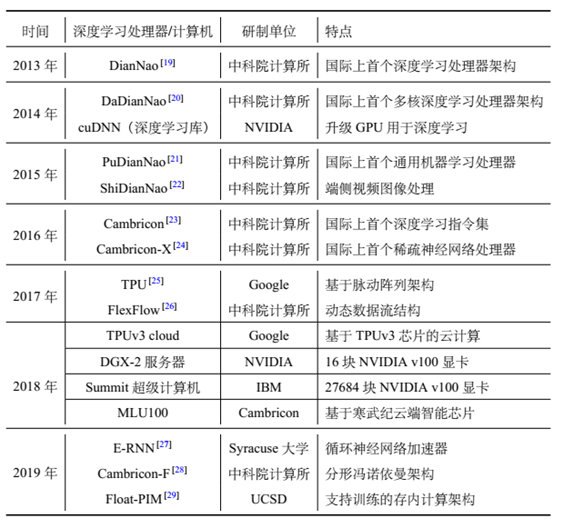
上图为2013年到2019年间深度学习处理器和计算机相关的重大成果统计。我们可以看到,Google不仅实现了Tensorflow,还设计了专用的TPU去支持tensorflow上的硬件加速。他们的贡献应该引起重视。
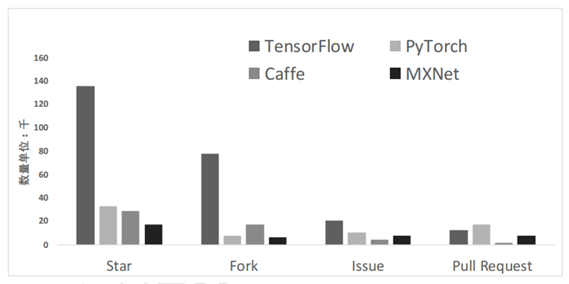
Tensorflow受欢迎的程度可谓一骑绝尘,可以说Tensorflow是当前智能计算系统的编程环境中不可或缺的一环。因此,我们得到一个结论,不论从分布式系统学习的角度、还是从硬件设计的角度;对Tensorflow的了解都是不可或缺的。
从Caffe谈起
Caffe是tensorflow的原形之一,因此我们先来聊一聊Caffe。在前tensorflow时代,caffe几乎是最受欢迎的深度学习框架。

从Caffe论文的引用数量我们就大致能知晓这一框架意义之深远。而事实上,Tensorflow在设计上也深受Caffe的影响。
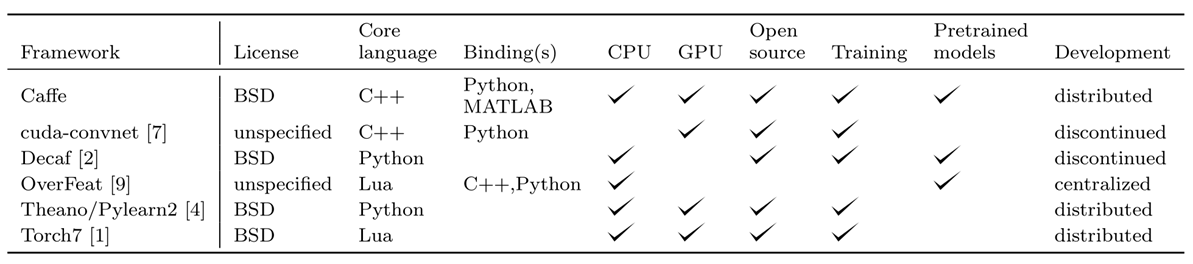
通过上表中的对比可知,Caffe开源,基于c++实现,支持异构计算;对当时的其它深度学习框架可称降维打击。
Caffe的亮点可以归纳如下:
- Modularity. 模块化的设计理念,保证了这一框架的可扩展性
- Test coverage. 每个模块的代码进行充分测试,未经测试的代码不会被合并
- Separation of representation and implementation. 神经网络的结构表示与功能实现分离,用户不必关注底层的实现
- Python and MATLAB bindings. 提供Python和MATLAB支持,在现有的机器学习代码的基础上进行快速原型
- Pre-trained reference models. 提供诸多已预训练的模型(例如 AlexNet),对用户友好
Caffe中的计算图机制也值得一提。在Caffe中,计算以层(Layer)为粒度,对应于神经网络中的层,为每一层给出了前向实现和反向实现。

Caffe固然是一个优秀的框架,但同样存在诸多缺陷:
- 在功能上有很多局限,例如对RNN类的网络支持有限、可部署的设备类型也受限
- 在易用性方面也被Pytorch等主流深度学习框架赶超
- 早期的Caffe版本已经不再维护更新
计算图的两种实现方式
在介绍Tensorflow之前,我们先强调一下计算图的两种主要实现机制——动态图和静态图。而这两种机制差异的本质是编程模式。动态图基于命令式编程,而静态图基于声明式编程
命令式编程:以命令序列的形式来表达程序执行的逻辑

声明式编程:以数据结构的形式来表达程序执行的逻辑
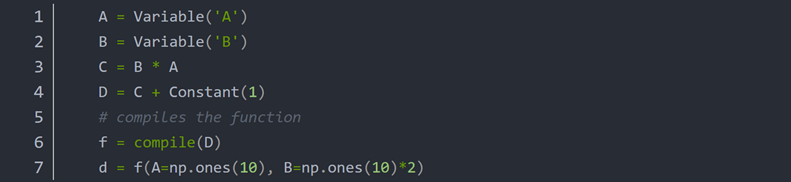
动态图和静态图的区别可归纳如下,
| 名称 | 动态计算图 | 静态计算图 |
|---|---|---|
| 编程模式 | 命令式编程 | 声明式编程 |
| 可调试性 | 容易调试 | 难于调试 |
| 优化程度 | 几乎没有 | 大幅优化 |
| 内存效率 | 低 | 高 |
| 计算效率 | 低 | 高 |
| 循环和控制 | 使用循环和控制命令即可 | 将控制流作为数据结构进行声明 |
Tensorflow的最初版本继承了Caffe的动态图机制,而Pytorch则采用了静态图机制。但两种框架目前都朝着兼容对方的feature的方向发展。
TensorFlow横空出世
Tensorflow 继承了几乎所有Caffe在设计上的优点,改善了Caffe的缺陷。再加上Google的背书,在开源社区和工业界都受到欢迎。
TensorFlow的亮点:
- 性能极佳,充分挖掘了并行能力
- 支持众多常见的前端语言, 覆盖云端到终端几乎所有的平台, 同时也有众多的辅助工具来支持多平台多设备使用
- 社区繁荣, 文档完善, 对初学者友好
TensorFlow的整体架构
TensorFlow中的主要组件包括:
- 面向各个语言的语言包
提供面向Python,GO等多种语言的支持,方便用户使用
- C/C++ API
基于TensorFlow的核心代码,使用C和C++语言封装了两套API,主要面向有高性能需求的用户
- 后端代码
主要由C++实现的Tensorflow功能后端,保证可移植性和性能
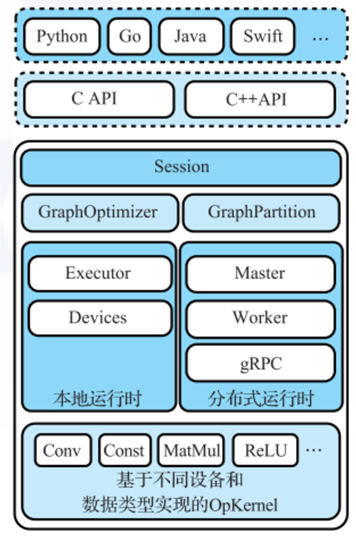
TensorFlow的基本运行流程
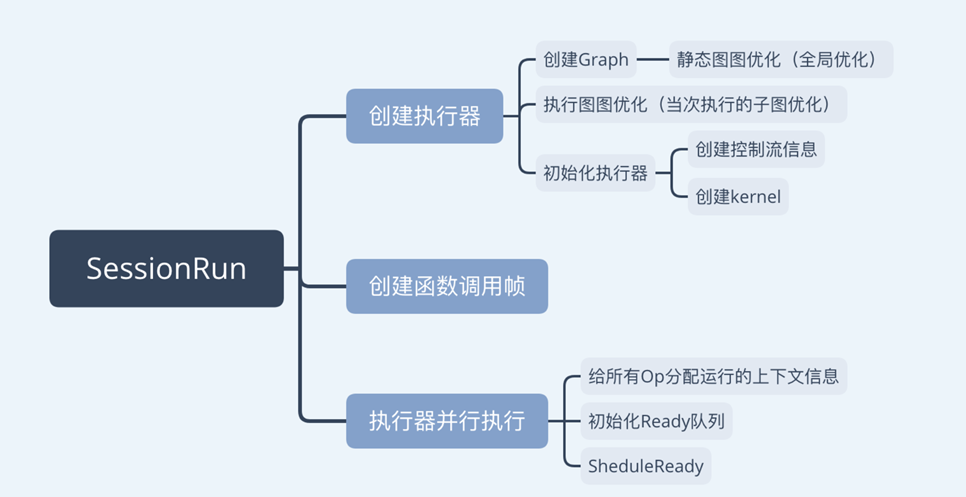
关于TensorFlow的运行流程和具体实现这一部分内容非常多。深入讲解与本篇博客的主题偏离的较远,因此这里不再展开。
这里只强调两点:
第一、对于TensorFlow的早期版本而言,只支持静态图的执行。
第二、TensorFlow的运行流程可以简要的概括为:用户利用TensorFlow提供的语言包进行声明式编程,定义网络结构。然后语言包通过调用名为Session.run的API将实际的执行交给后端完成。
TensorFlow设计之妙
1.TensorFlow中的计算图设计
TensorFlow中定义了Operation作为计算图结构和功能上的基本单元。 TensorFlow中实现了多种Operation,支持加载输入、进行运算、检查点以及循环控制定义等功能;
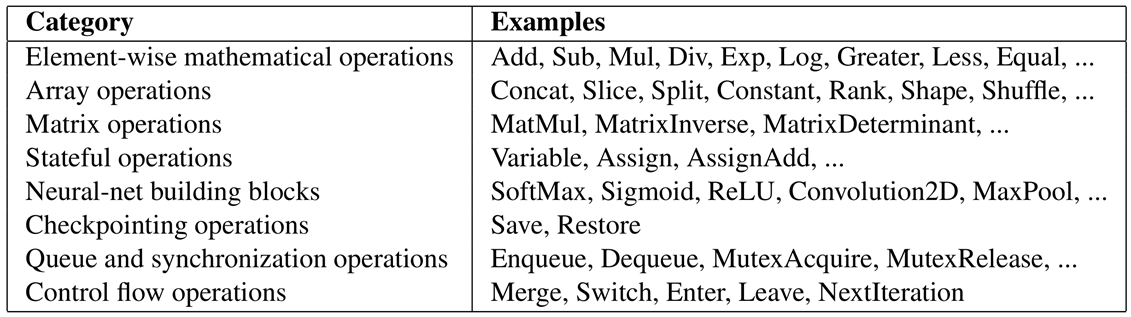
常见的Operation如上图所示。
不同功能的操作在计算图中继承同一基类具备以下优势:
第一、某些公共的方法不必重复去实现,例如设置Operation的名称。
第二、在下文中我们会看到对计算图的全局优化和自动求导等操作都需要在图上进行遍历;当计算图中的各单元都继承相同的基类时,我们的遍历操作更容易实现、也更加安全。
2.计算图的自动求导机制
深度学习网络的执行过程一般可以归纳为三个步骤——第一、前向传播计算loss;第二、反向传播计算梯度;第三、更新参数。
其中梯度计算是整个算法的核心,因此我们介绍Tensorflow中的梯度计算机制。

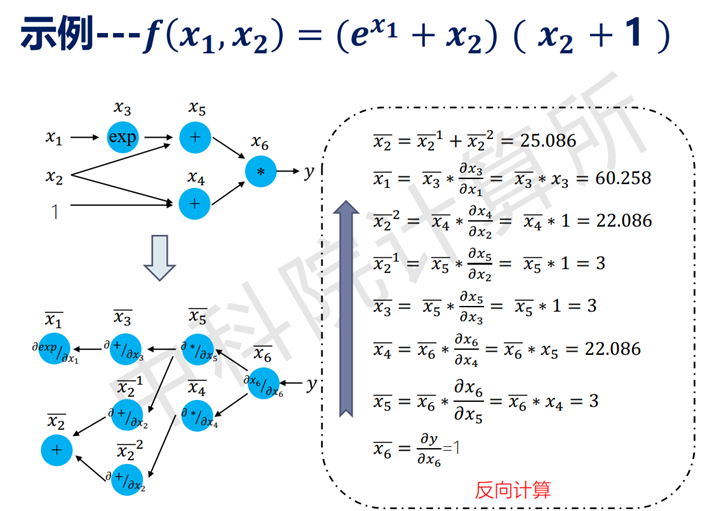
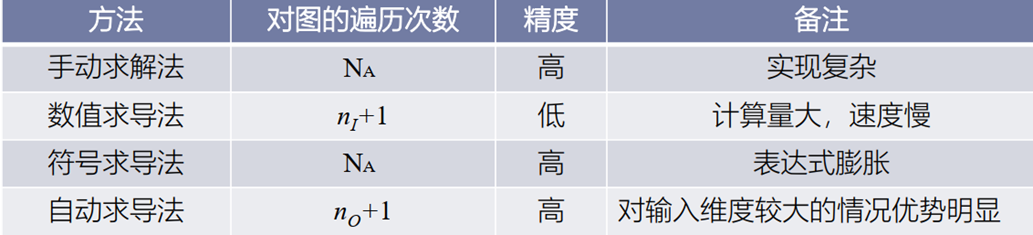
自动求导机制与其他常见求导方式对比如下:
该求导方式的优点可归纳如下:
灵活,框架可以完全向用户隐藏求导过程。用户只需描述前向计算的过程, 由编程框架自动推导反向计算图, 完成导数计算
只对基本函数运用符号求导法, 因此可以灵活结合编程语言的循环结构、条件结构等进行求导
3.计算图的执行模式
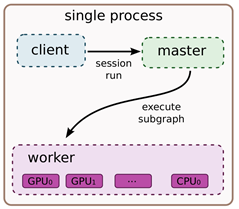
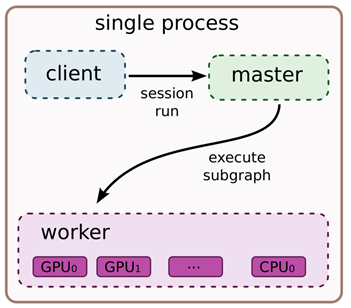
计算图的本地执行模式中有如下要件:
- client:通过session接口与master和worker通信
- master:控制所有的worker按照计算图执行
- worker:每一个worker负责一个或多个计算设备的仲裁访问,并根据master的指令,执行这些计算设备中的计算图
- 设备:CPU、GPU、TPU和其他类型的加速器,此外TensorFlow支持自定义设备的注册
首先考虑最简单的执行场景: 一个worker进程中仅包含一个设备的情况。 在该情况下:
一、 计算图按照节点(对应计算图中的Operation)之间的依赖关系顺序执行 二、每个节点有一个计数器, 记录其依赖节点中尚未执行的节点数量, 一个节点执行完成, 则其所有依赖节点的计数器计数递减
三、当计数器计数为0时, 则该节点可以执行, 并将其添加到就绪队列中
当本地存在多个可用设备时,计算图需经过一系列处理后分配到各设备上运行。
处理流程总结如下:
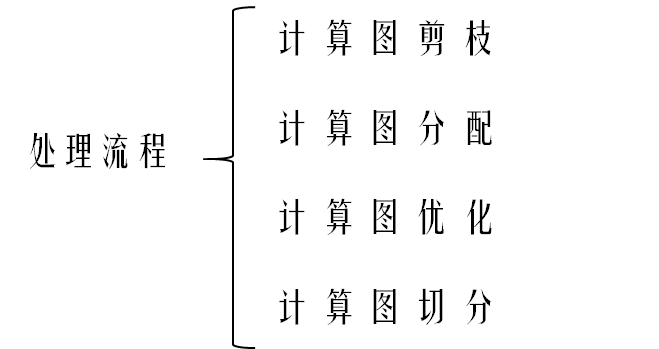
计算图剪枝

计算图分配

计算图优化
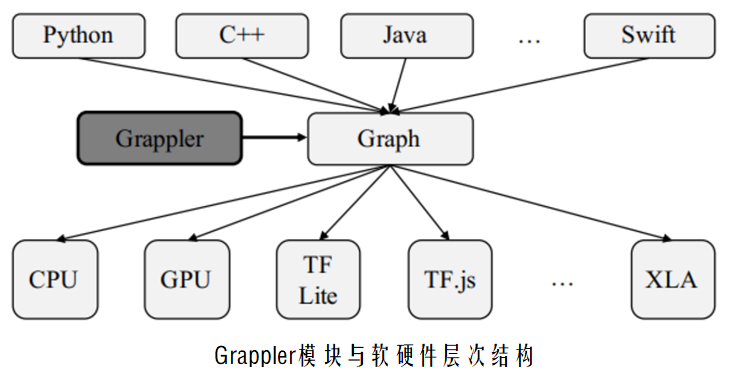
TensorFlow中的图优化由Grappler模块来实现
通过图优化, 可以根据不同的硬件结构调整计算调度策略, 从 而获得更快的计算速度和更高的硬件利用率 也能减少推断过程中所需的峰值内存, 从而运行更大的模型
在TensorFlow中计算图优化的常见技术如下:


计算图切分
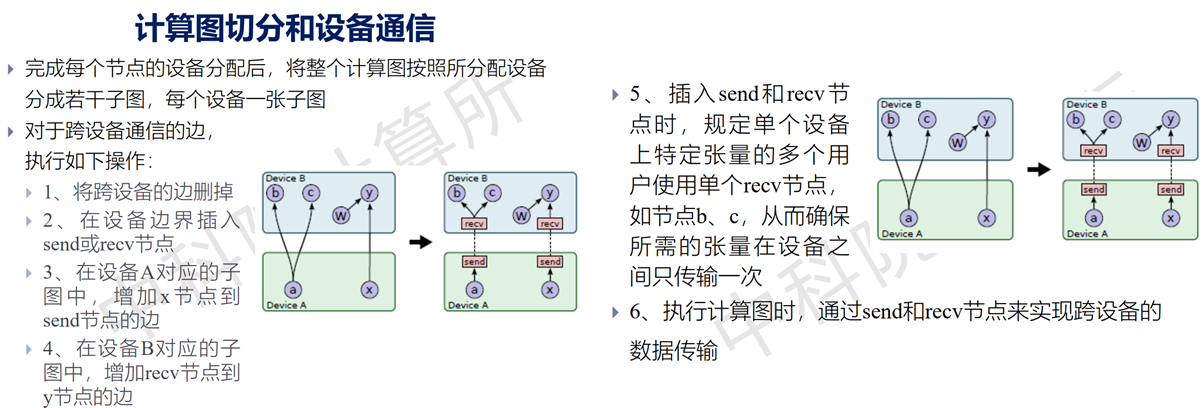
这里有一个需要注意的点:本地多设备执行其实和分布式执行的机制是相同的;send和recv在本地通过总线或者NV-LINK协议实现数据传输,在分布式的情况下,往往通过TCP或者RDMA保证数据的可靠传输。Google的架构师通过这种方式实现了本地执行和分布式执行的统一化,在笔者看来十分优雅。
4.TensorFlow增加同步并行效率的设计技巧
TensorFlow中的并行方式包含以下几种:
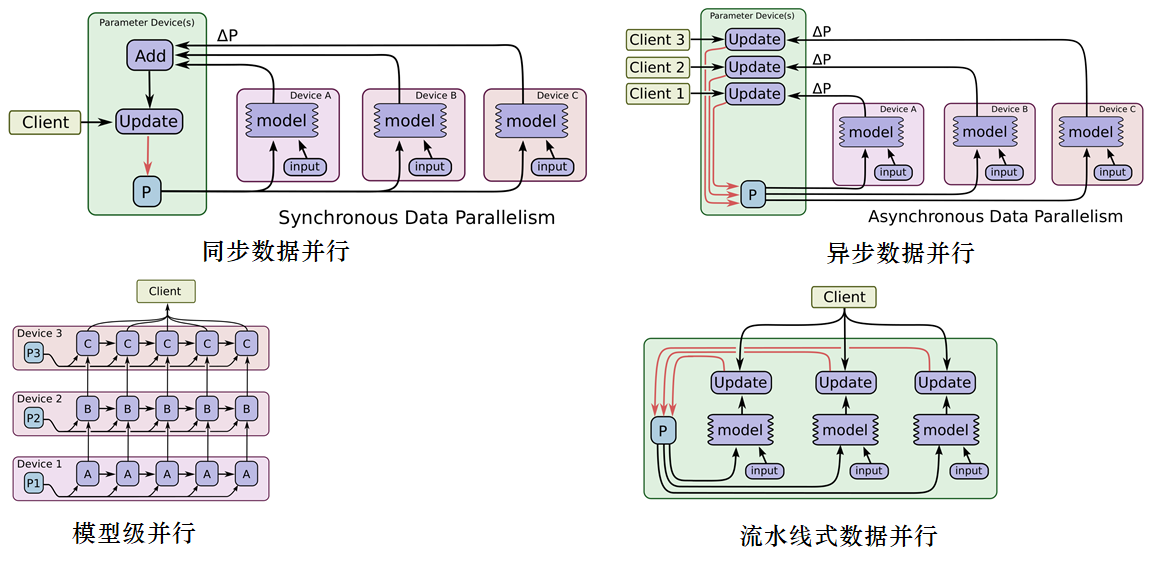
同步数据并行策略的吞吐量相对于异步数据并行策略小,但是往往有更快的收敛速度。Tensorflow 采用了一种特殊的方式,通过增加冗余资源来保证同步数据并行能达到近似异步数据并行的效率。
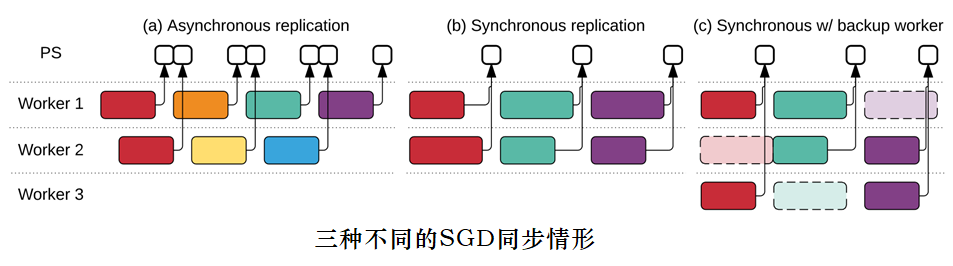
1、在异步情况(a)下,每个worker在步骤开始时读取参数,并将梯度异步地更新到参数并应用到自身——确保了高吞吐率,但各worker中常使用过时的参数,不是非常有效。
2、同步情况使用队列协调执行:将阻塞队列作为Barrier,以确保所有worker读取相同的参数,另一个队列收集多个梯度更新,并以原子方式应用参数。(b)情形下总吞吐量受限制。
3、为了解决较低效率的worke造成的瓶颈,实现了备份worker如所示(c),这与MapReduce的备份任务机制类似。 系统周期性检测是否存在落后woker – 若存在、则备份worker主动运行,聚集将采用3个更新中的前2个。
该技术对于吞吐量和加速比的提升非常明显,下图为Google的实验结果。

这个设计技巧虽然简单粗暴,但是十分有效。通过增加少许计算资源突破瓶颈;是一种值得学习的设计思路。
游戏软件工程基础
3.2 c/c++的数据、代码及内存
数据
最流行的定义浮点数标准是IEEE-754,其最高有效位是符号位,紧随其后的是8位指数和23位尾数。
IEEE 32位浮点数可表示的最大值为3.403*10^38;可表示的最小非0值为1.175*10^-38。epsilon为1.192*10^-7(epsiison 表示1+e=1的最大值)。
有限精度和机器epsilon的概念,在程序设计的过程中非常有用,将该要素纳入考虑能够避免很多预期外的情况发生。
内存布局
可执行和可链接格式(executable and linkable format, ELF)是链接器创建的一种可执行文件格式。在UNIX平台上使用.elf扩展名,在Windows平台上使用.exe扩展名。
可执行映像,一般最少由以下几个段组成
- 代码段:包含程序中定义的全部函数的可执行机器码。
- 数据段:包含全部获初始化的全局及静态变量,链接器会填入适当的初始值。
- BSS段:包含全部未初始化的全局及静态变量。根据C/C++的定义,任何未初始化的全局变量和静态变量均为0。链接器只简单地存储所需零值的个数在可执行映像中。当操作系统载入程序时,会保留BSS所需的字节个数。并为该部分内存填入0。
- 只读数据段:又称
rodata段,包含所有浮点常量及所有用const声明的全局对象实例。
程序堆栈
略
对象的内存布局
对齐和包裹
数据对象的对齐是指,其内存地址是否为对齐字节大小的倍数(通常是2的幂)。对齐是重要的。因为现在许多处理器实际上只能正常地读/写已对齐的数据块。
作为一个良好的经验法则,数据类型应该需要其字节大小的对齐。包含4个浮点数的SIMD矢量通常需要16字节对齐。
整个结构的对齐需求等于其成员中的最大对齐需求。
C++中类的布局
C++中的类有别于C的结构有二
GIT 入门
git 是目前最常用的分布式版本控制系统,由 linus 开发。
包括GitHub在内的许多代码托管网站均使用git作为版本控制器。
1. 简单的GIT命令
简单的 git 命令如下:
git init //初始化一个代码库
git add //把工作区的修改,提交到暂存区
git commit //把暂存区的修改,保存至本地库
git push //把本地库的记录,推送至远程库2. 版本管理
2.1. 工作区与暂存区
要随时掌握工作区的状态,使用git status命令。
如果git status告诉你有文件被修改过,用git diff可以查看修改内容。
git add命令实际上就是把要提交的所有修改放到暂存区(Stage),然后,执行git commit就可以一次性把暂存区的所有修改提交到分支。
$ git commit -m "**understand** how stage works"
[master e43a48b] understand how stage works
2 files changed, 2 insertions(+)
create mode 100644 LICENSE一旦提交后,如果你又没有对工作区做任何修改,那么工作区就是“干净”的:
$ git status
On branch master
nothing to commit, working tree clean现在版本库变成了这样,暂存区就没有任何内容了:

2.2. 版本回退
现在总结一下:
HEAD指向的版本就是当前版本,因此,Git允许我们在版本的历史之间穿梭,使用命令git reset --hard commit_id。
穿梭前,用git log可以查看提交历史,以便确定要回退到哪个版本。
要重返未来,用git reflog查看命令历史,以便确定要回到未来的哪个版本。
2.3. 撤销修改
场景1:当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令git checkout -- file。
场景2:当你不但改乱了工作区某个文件的内容,还添加到了暂存区时,想丢弃修改,分两步,第一步用命令git reset HEAD <file>,就回到了场景1,第二步按场景1操作。
2.4. 删除文件
命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。
3. 远程仓库
我们可以通过类似Github的代码托管网站使用git来管理我们的代码
3.1. 添加远程库
要关联一个远程库,使用命令git remote add origin git@server-name:path/repo-name.git;
关联后,使用命令git push -u origin master第一次推送master分支的所有内容;
此后,每次本地提交后,只要有必要,就可以使用命令git push origin master推送最新修改;
3.2. 从远程库克隆
要克隆一个仓库,首先必须知道仓库的地址,然后使用git clone命令克隆。
Git支持多种协议,包括https,但通过ssh支持的原生git协议速度最快。
4. 分支管理
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN。
如果两个平行宇宙互不干扰,那对现在的你也没啥影响。不过,在某个时间点,两个平行宇宙合并了,结果,你既学会了Git又学会了SVN!

4.1. 创建与合并分支
Git鼓励大量使用分支:
查看分支:git branch
创建分支:git branch <name>
切换分支:git checkout <name>或者git switch <name>
创建+切换分支:git checkout -b <name>或者git switch -c <name>
合并某分支到当前分支:git merge <name>
删除分支:git branch -d <name>
4.2. 解决冲突
当Git无法自动合并分支时,就必须首先解决冲突。解决冲突后,再提交,合并完成。
解决冲突就是把Git合并失败的文件手动编辑为我们希望的内容,再提交。
用git log --graph命令可以看到分支合并图。
4.3. 分支策略
通常,合并分支时,如果可能,Git会用Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息。
如果要强制禁用Fast forward模式,Git就会在merge时生成一个新的commit,这样,从分支历史上就可以看出分支信息。
下面我们实战一下--no-ff方式的git merge:
首先,仍然创建并切换dev分支:
$ git checkout -b dev
Switched to a new branch 'dev'修改readme.txt文件,并提交一个新的commit:
$ git add readme.txt
$ git commit -m "add merge"
[dev f52c633] add merge
1 file changed, 1 insertion(+)现在,我们切换回master:
$ git checkout master
Switched to branch 'master'准备合并dev分支,请注意--no-ff参数,表示禁用Fast forward:
$ git merge --no-ff -m "merge with no-ff" dev
Merge made by the 'recursive' strategy.
readme.txt | 1 +
1 file changed, 1 insertion(+)因为本次合并要创建一个新的commit,所以加上-m参数,把commit描述写进去。
合并后,我们用git log看看分支历史:
$ git log --graph --pretty=oneline --abbrev-commit
* e1e9c68 (HEAD -> master) merge with no-ff
|\
| * f52c633 (dev) add merge
|/
* cf810e4 conflict fixed
...在实际开发中,我们应该按照几个基本原则进行分支管理:
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
那在哪干活呢?干活都在dev分支上,也就是说,dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;
你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
4.4. Bug分支
修复bug时,我们会通过创建新的bug分支进行修复,然后合并,最后删除;
当手头工作没有完成时,先把工作现场git stash一下,然后去修复bug,修复后,再git stash pop,回到工作现场;
在master分支上修复的bug,想要合并到当前dev分支,可以用git cherry-pick <commit>命令,把bug提交的修改“复制”到当前分支,避免重复劳动。
4.5. Feature分支
开发一个新feature,最好新建一个分支;
如果要丢弃一个没有被合并过的分支,可以通过git branch -D <name>强行删除。
4.6. 多人协作
查看远程库信息,使用git remote -v;
本地新建的分支如果不推送到远程,对其他人就是不可见的;
从本地推送分支,使用git push origin branch-name,如果推送失败,先用git pull抓取远程的新提交;
在本地创建和远程分支对应的分支,使用git checkout -b branch-name origin/branch-name,本地和远程分支的名称最好一致;
建立本地分支和远程分支的关联,使用git branch --set-upstream branch-name origin/branch-name;
从远程抓取分支,使用git pull,如果有冲突,要先处理冲突。
5. 标签管理
5.1. 创建标签
命令git tag <tagname>用于新建一个标签,默认为HEAD,也可以指定一个commit id;
命令git tag -a <tagname> -m "blablabla..."可以指定标签信息;
命令git tag可以查看所有标签。
5.2. 操作标签
命令git push origin <tagname>可以推送一个本地标签;
命令git push origin --tags可以推送全部未推送过的本地标签;
命令git tag -d <tagname>可以删除一个本地标签;
命令git push origin :refs/tags/<tagname>可以删除一个远程标签。
6. 使用GitHub
在GitHub上,可以任意Fork开源仓库;
自己拥有Fork后的仓库的读写权限;
可以推送pull request给官方仓库来贡献代码。
7. 自定义Git
7.1. 忽略特殊文件
忽略某些文件时,需要编写.gitignore;
.gitignore文件本身要放到版本库里,并且可以对.gitignore做版本管理!
DIANNAO论文导读
DIANNAO系列论文是寒武纪人工智能加速芯片的理论依据。
对于研究人工智能硬件加速领域的学者而言,DIANNAO系列论文是不可不读的经典之作。
DIANNAO的前世今生

本文是对 DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning 的内容做一个简介
论文简介
作者认为截止到2014年为止体系结构领域存在三大趋势:
- 异构多核架构成为主流
- 需要高效灵活的加速器
- 许多新的高性能及嵌入式应用和所有的人工智能应用都依赖于机器学习
- 需要优化机器学习的性能
- 基于神经网络(尤其是CNN和DNN)的有限几种技术在许多应用场景中都是最有效且最先进的。
- 对CNN和DNN等少数几种算法进行优化
于是得出结论:设计一种专门加速CNN和DNN的加速器的需求非常合理且迫切。
那么他们是否成功了呢?
事实证明他们成功了,并提出了一种65nm的设计,该设计可以在每3.02mm2的空间、485mW的功耗(不包括主存储器访问)每1.02ns并行执行496个16位定点运算,即452 GOP / s。在CNN和DNN中建立的10层最大网络中,该加速器比时钟频率为2GHz的128位SIMD内核平均快117.87倍,能源效率(包括主存储器访问)平均提高21.08倍。
以上为该芯片的布局图
于是问题来了, 怎样的设计能达到这样的性能我们先介绍一下一些必须知道的CNN性质再回答这个问题
基础知识
Processing vs. training.
在工业界,离线训练往往比在线训练更有效且更常见。所以本文作者专注于前馈网络进行加速。(注意反向传播性质与前馈网络的计算与内存访问模式相似。所以在未来的研究中有可能支持训练)
General structure.
卷积神经网络的一般结构如下:
卷积、池化、分类是卷积神经网络中的一般操作。我们分别讲解一下它们的特征
Convolutional layers.
一个简单的卷积映射如下图所示。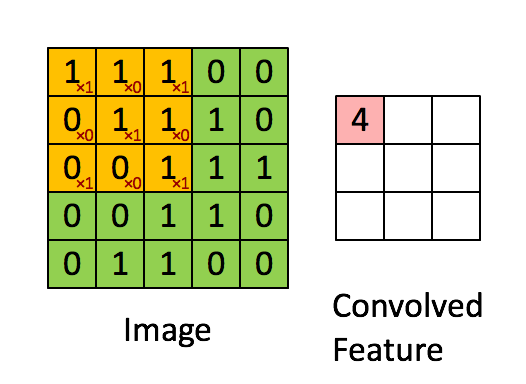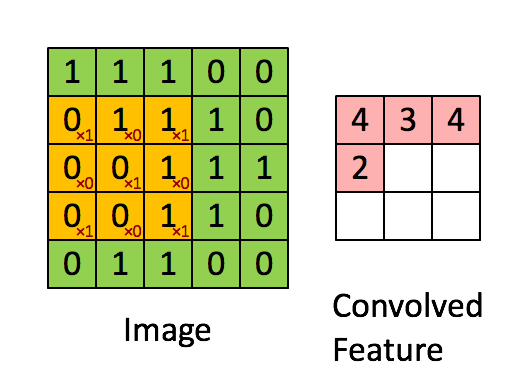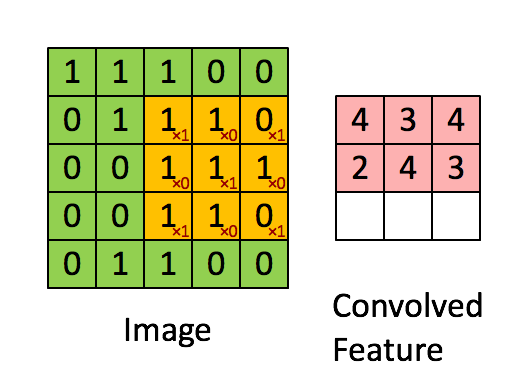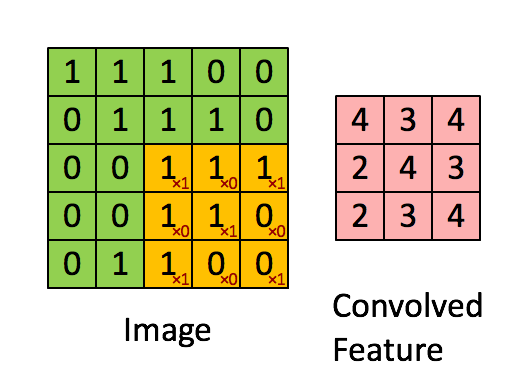
更一般的卷积映射如下
存在多个输入特征图和输出特征图。图中动态显示了计算其中一层输出特征图的状态。每一层输出特征图的计算逻辑都是相同的,但不同层的计算使用的kernel或者说filter是不同的;图中左边的kernel是另一个输出图层所使用的。
这里强调一下 private kernel 和 shared kernel的 区别:
每个时间步在动图上计算一个结果,privete kernel 就意味着每个时间步使用的 kernel 都不一样
文章中给出了一个卷积层运算的示意图,这里把输入特征图叠到一起,把输出特征图叠到一起。图中表示进行单个上图中的映射计算。
Pooling layers.
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是22大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角22池化区域的max-pooling结果,取该区域的最大值max(0.77,-0.11,-0.11,1.00),作为池化后的结果,如下图: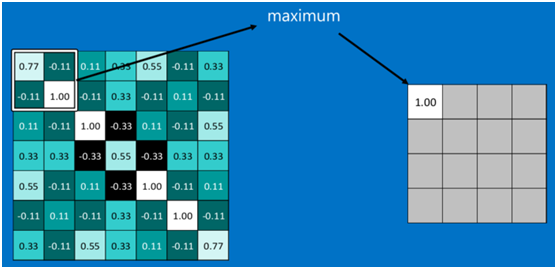
池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图: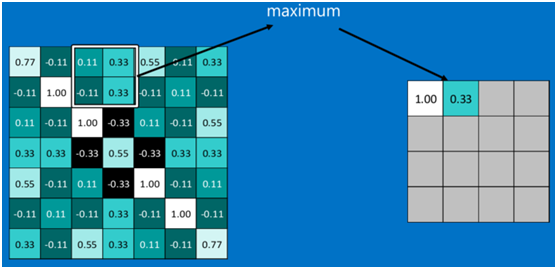
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下: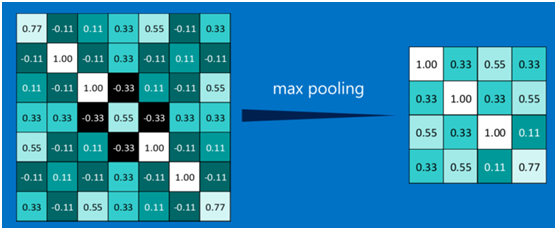
对所有的feature map执行同样的操作,结果如下:
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
更一般的池化如左图所示,其实就是独立的对每一个特征图进行池化。运算上比卷积层更加简单。

Classifier Layers.
在分类之前,先对特征图进行平展化(也就是把图展开成一维数据)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:**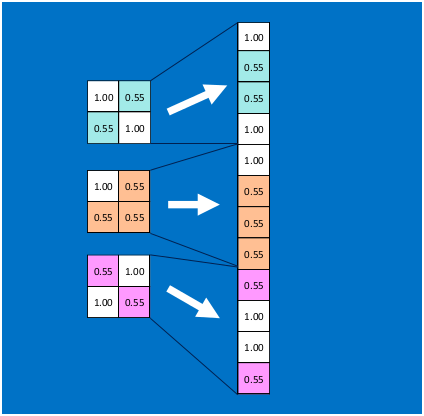
** 由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)**

** 在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)**
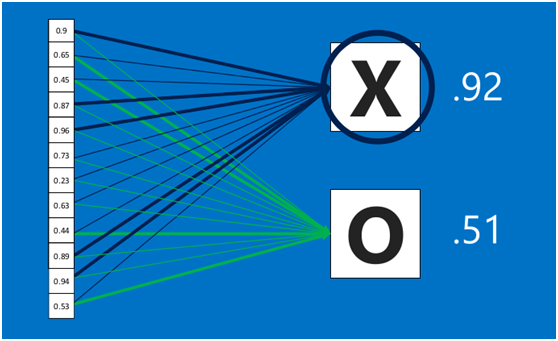
** 上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:**
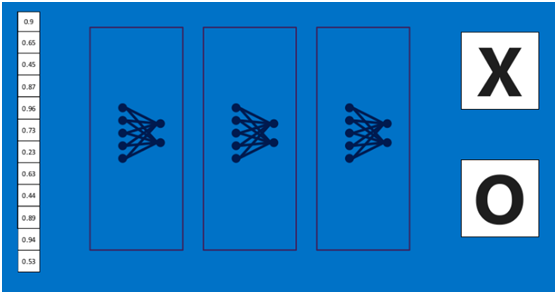 **
**
更一般的全连接图文章中如下:
为什么不直接用硬件去实现大规模神经网络?
就运算符而言,它对应于两个16x1 16位多路复用器(用于段边界选择,即xi,xi + 1),一个16位乘法器(16位输出)和一个16位加法器执行插值。
16段系数(ai; bi)存储在一个小RAM中; 这仅通过改变RAM段系数ai就可以实现任何功能,而不仅是S形(例如,双曲正切,线性函数等); 双段边界(xi; xi + 1)是硬连线的。
但是,面积,能量和延迟随着神经元数量的增加而平方增长。
考虑到大规模神经网络中的神经元数以千计,仅一层的完整硬件布局范围就可能在数百或数千mm2之间,因此,这种方法对于大规模神经网络是不现实的。
想要保证加速器计算密度较高,最多一部分神经元和突触可以在硬件中实现
因此加速器件需要在内存层次和计算层次架构得更加合理
Large-scale Neural Networks(图为深度卷积网络VGGNET)

现在的神经网络规模都是非常大的。运算数据不可能完全装进L1 Cache!(甚至L2 Cache)
数据换入换出将导致巨大开销。而计算上的优化前人已经做的非常好了,根据Amdahl定律减少内存传输的代价才能最大程度优化该算法。
优化方式
假设:
使用了含缓存的加速器。
缓存层次结构受Intel Core i7启发:
L1为32KB,每行64字节,8路;
L2为2MB,每行64字节,8路。
与Core i7不同,我们假设高速缓存具有足够的存储体/端口来为neuron数组提供Tn×4字节,为synapse数组提供Tn×Ti×4字节。能将TiTn的二层循环内的数据的TiTn次串行计算并行化。
e.g.
对于太大的Tn和Ti值。此类缓存的成本可能令人望而却步
在我们的实验中,我们使用Tn = Ti = 16。
作者分别用tiled算法优化了算法的三个不同部分。优化结果如下:

以上是benchmark规模
加速器架构

加速器由NFU/stroage/CP三部分组成
NFU
NFU有一下三个特性
· Staggered pipeline
通过流水线提升运行效率
· NFU-3 function implementation
前文中已表示了神经网络中激励函数的实现方式,下文不在赘述
· 16-bit fixed-point arithmetic operators
使用16位定点运算部件
Storage
Q:为什么切分buffer?使用单个多端口buffer似乎更加方便?
A:Concerning Width & Conflicts
拆分结构的第一个好处是将SRAM调整为适当的读/写宽度。
NBin和NBout的宽度均为Tn×2字节,而SB的宽度为Tn×Tn×2字节。
单个读取宽度大小(例如,与高速缓存行大小相同)将是较差的权衡。
如果将其调整为突触,即,如果行大小为Tn×Tn×2,则从Tn×Tn×2宽数据库中读取Tn×2个字节会产生巨大的能量损失,请参见图13,该图表明 对于65nm的TSMC工艺,SRAM读取的能量是存储区宽度的函数。
如果将行大小调整为适合神经元,即,如果行大小为Tn×2,则读取Tn×Tn×2个字节会耗费大量时间。
将存储分为专用结构可以为每个读取请求获得最佳时间和精力。
冲突。
拆分存储结构的第二个好处是避免发生冲突,就像在高速缓存中那样。
由于我们出于成本和能源(泄漏)的原因要使存储结构的尺寸保持较小,这一点尤其重要。
替代解决方案是使用高度关联的缓存。
请考虑以下约束条件:高速缓存行(或端口数量)需要很大(Tn×Tn×2),才能以较高的速率服务于突触; 因为我们希望保持高速缓存的大小很小,所以忍受这么长的高速缓存行的唯一选择是高关联性。
但是,在n路高速缓存中,通过推测性地并行读取所有n路/存储库来实现快速读取。
结果,关联缓存的能量成本迅速增加。
即使是从8路关联的32KB高速缓存中读取64字节,其能耗也比从直接映射的高速缓存中32字节读取65nm的能耗高3.15倍。
使用CACTI进行的测量[40]。
即使仅使用64字节的行,Core i7的第一级32KB数据高速缓存已经是8路关联的,因此我们需要具有很大行的更大关联性(对于Tn = 16,行大小为 512字节长)。
换句话说,在我们的案例中,高度关联的缓存将是昂贵的能源解决方案。
分离存储和对位置行为的精确了解可以完全消除数据冲突。
Exploiting the locality of inputs and synapses
DMAs
Rotating NBin buffer for temporal reuse of input neurons(pooling和conv存在overlap)
Local transpose in NBin for pooling layers
DMA。
对于空间局部性开发,我们实现了三个DMA,每个缓冲区一个(两个负载DMA,一个用于输出的存储DMA)。
DMA请求以指令形式发送给NBin,稍后在第5.3.2节中进行描述。
这些请求被缓冲在与每个缓冲区关联的单独的FIFO中(参见图11),并且在DMA发送了前一条指令的所有存储请求后立即发出这些请求。
这些DMA请求FIFO可以将发出给所有缓冲区和NFU的请求与当前缓冲区和NFU操作解耦。
因此,只要有足够的缓冲区容量,就可以提前预装DMA请求以容忍较长的等待时间。
这种预加载类似于预取,尽管没有推测。
由于NBin(和SB)同时用作重用和预加载缓冲器的暂存器,因此我们使用了双端口SRAM。
台积电(TSMC)65nm库将64项NB的双端口SRAM的读取能量开销估计为24%。
旋转NBin缓冲区,可暂时重用输入神经元。
所有层的输入都分成适合NBin的块,并通过将NBin实现为循环缓冲区来重用它们。
实际上,轮换自然是通过更改寄存器索引来实现的,就像在软件实现中一样,缓冲区条目没有物理(且昂贵)的移动。
NBin中的本地转置用于池化层。
卷积层和池化层之间对于(输入)神经元的数据结构组织存在紧张关系。
如前所述,Kx; Ky通常很小(通常小于10),Ni大约大一个数量级。
因此,将输入要素映射作为三维神经元数据结构的最内层索引,内存提取会更有效(长步1访问)。
然而,这对于合并层是不方便的,因为每个输入特征图仅计算一个输出,即仅使用Kx×Ky数据(而在卷积层中,需要所有Kx×Ky×Ni数据来计算一个输出数据)。
结果,对于池层,逻辑数据结构组织将具有kx; ky作为最里面的尺寸,以便将计算一个输出所需的所有输入连续存储在NBin缓冲区中。
我们通过在NBin中引入映射函数来解决此问题,该函数具有局部转置循环ky的作用; kx和循环i,以便沿循环i加载数据,但将其存储在NBin中,然后沿循环ky发送到NFU; kx首先; 这是通过在加载数据时将数据插入NBin来实现的,请参见图14。
如第3节所述,对于突触和SB,没有重用(分类器层,具有专用内核和池化层的卷积层),也没有在卷积层中重用共享内核。
对于输出和NBout,我们需要重用部分和,即 ,参见图5中的参考sum [n]。这种重用需要在下一节中说明的其他硬件修改。
Exploiting the locality of outputs.
Dedicated registers
Circular buffer (reuse NBout) 绝妙的观察!
是否活跃 NFU-1 NFU-2 NFU-3 POOL √ √ × CONV √ √ if 写入Nbout then 活跃 /if 不写入 Nbout 不活跃 CLASS √ √ if 写入Nbout then 活跃 /if 不写入 Nbout 不活跃