DIANNAO论文导读
DIANNAO论文导读
DIANNAO系列论文是寒武纪人工智能加速芯片的理论依据。
对于研究人工智能硬件加速领域的学者而言,DIANNAO系列论文是不可不读的经典之作。
DIANNAO的前世今生

本文是对 DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning 的内容做一个简介
论文简介
作者认为截止到2014年为止体系结构领域存在三大趋势:
- 异构多核架构成为主流
- 需要高效灵活的加速器
- 许多新的高性能及嵌入式应用和所有的人工智能应用都依赖于机器学习
- 需要优化机器学习的性能
- 基于神经网络(尤其是CNN和DNN)的有限几种技术在许多应用场景中都是最有效且最先进的。
- 对CNN和DNN等少数几种算法进行优化
于是得出结论:设计一种专门加速CNN和DNN的加速器的需求非常合理且迫切。
那么他们是否成功了呢?
事实证明他们成功了,并提出了一种65nm的设计,该设计可以在每3.02mm2的空间、485mW的功耗(不包括主存储器访问)每1.02ns并行执行496个16位定点运算,即452 GOP / s。在CNN和DNN中建立的10层最大网络中,该加速器比时钟频率为2GHz的128位SIMD内核平均快117.87倍,能源效率(包括主存储器访问)平均提高21.08倍。
以上为该芯片的布局图
于是问题来了, 怎样的设计能达到这样的性能我们先介绍一下一些必须知道的CNN性质再回答这个问题
基础知识
Processing vs. training.
在工业界,离线训练往往比在线训练更有效且更常见。所以本文作者专注于前馈网络进行加速。(注意反向传播性质与前馈网络的计算与内存访问模式相似。所以在未来的研究中有可能支持训练)
General structure.
卷积神经网络的一般结构如下:
卷积、池化、分类是卷积神经网络中的一般操作。我们分别讲解一下它们的特征
Convolutional layers.
一个简单的卷积映射如下图所示。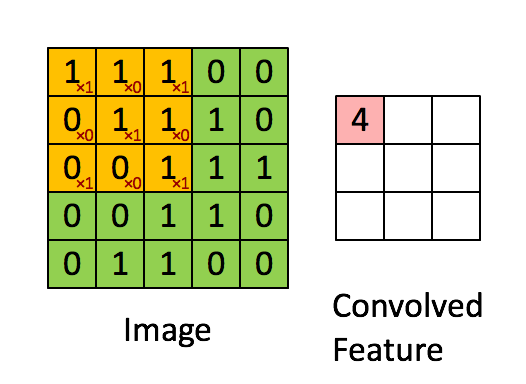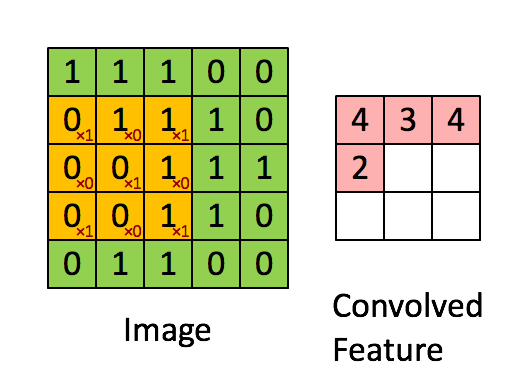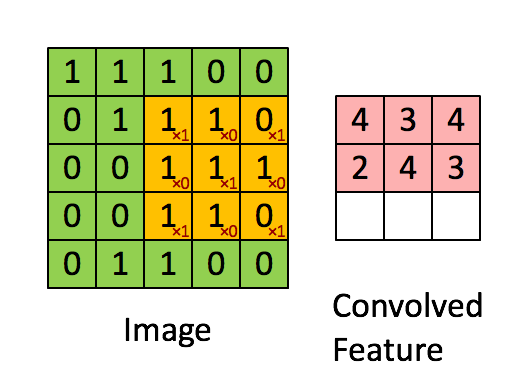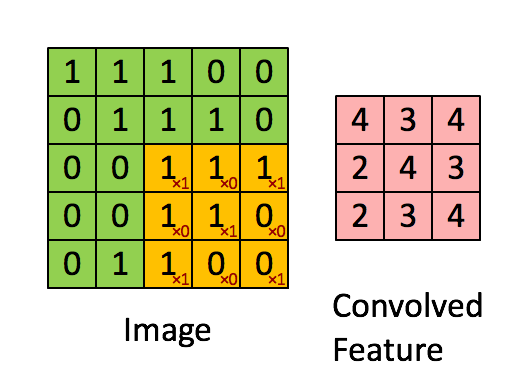
更一般的卷积映射如下
存在多个输入特征图和输出特征图。图中动态显示了计算其中一层输出特征图的状态。每一层输出特征图的计算逻辑都是相同的,但不同层的计算使用的kernel或者说filter是不同的;图中左边的kernel是另一个输出图层所使用的。
这里强调一下 private kernel 和 shared kernel的 区别:
每个时间步在动图上计算一个结果,privete kernel 就意味着每个时间步使用的 kernel 都不一样
文章中给出了一个卷积层运算的示意图,这里把输入特征图叠到一起,把输出特征图叠到一起。图中表示进行单个上图中的映射计算。
Pooling layers.
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是22大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角22池化区域的max-pooling结果,取该区域的最大值max(0.77,-0.11,-0.11,1.00),作为池化后的结果,如下图: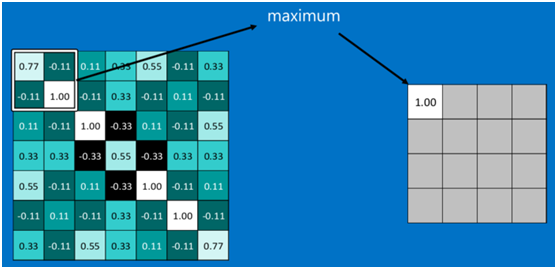
池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图: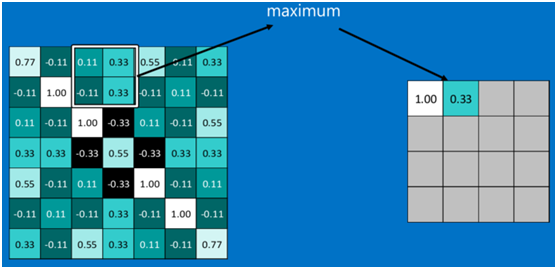
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下: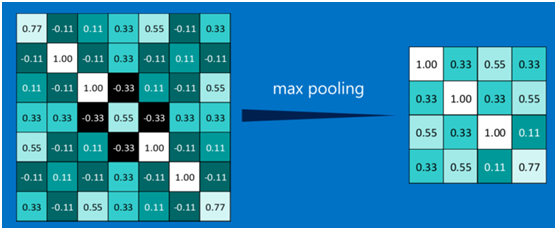
对所有的feature map执行同样的操作,结果如下:
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
更一般的池化如左图所示,其实就是独立的对每一个特征图进行池化。运算上比卷积层更加简单。

Classifier Layers.
在分类之前,先对特征图进行平展化(也就是把图展开成一维数据)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
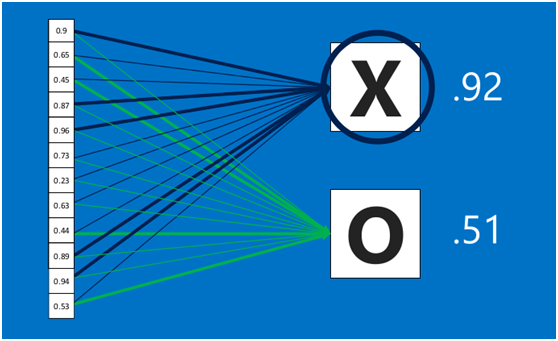
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:**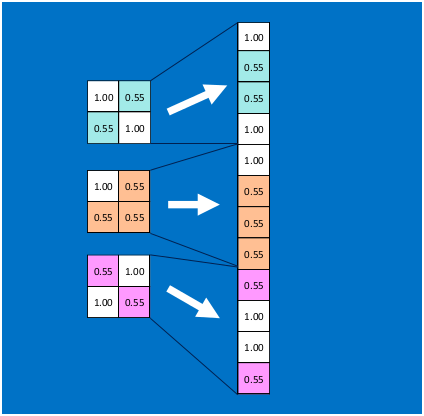
** 由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)**

** 在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)**
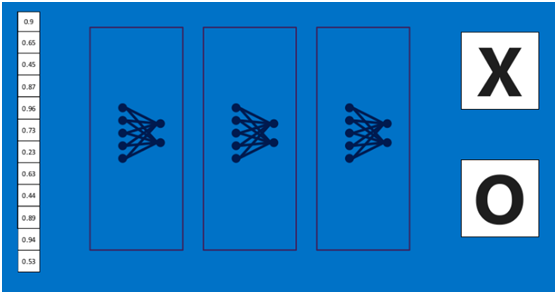
** 上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:**
 **
**
更一般的全连接图文章中如下:
为什么不直接用硬件去实现大规模神经网络?
就运算符而言,它对应于两个16x1 16位多路复用器(用于段边界选择,即xi,xi + 1),一个16位乘法器(16位输出)和一个16位加法器执行插值。
16段系数(ai; bi)存储在一个小RAM中; 这仅通过改变RAM段系数ai就可以实现任何功能,而不仅是S形(例如,双曲正切,线性函数等); 双段边界(xi; xi + 1)是硬连线的。
但是,面积,能量和延迟随着神经元数量的增加而平方增长。
考虑到大规模神经网络中的神经元数以千计,仅一层的完整硬件布局范围就可能在数百或数千mm2之间,因此,这种方法对于大规模神经网络是不现实的。
想要保证加速器计算密度较高,最多一部分神经元和突触可以在硬件中实现
因此加速器件需要在内存层次和计算层次架构得更加合理
Large-scale Neural Networks(图为深度卷积网络VGGNET)

现在的神经网络规模都是非常大的。运算数据不可能完全装进L1 Cache!(甚至L2 Cache)
数据换入换出将导致巨大开销。而计算上的优化前人已经做的非常好了,根据Amdahl定律减少内存传输的代价才能最大程度优化该算法。
优化方式
假设:
使用了含缓存的加速器。
缓存层次结构受Intel Core i7启发:
L1为32KB,每行64字节,8路;
L2为2MB,每行64字节,8路。
与Core i7不同,我们假设高速缓存具有足够的存储体/端口来为neuron数组提供Tn×4字节,为synapse数组提供Tn×Ti×4字节。能将TiTn的二层循环内的数据的TiTn次串行计算并行化。
e.g.
对于太大的Tn和Ti值。此类缓存的成本可能令人望而却步
在我们的实验中,我们使用Tn = Ti = 16。
作者分别用tiled算法优化了算法的三个不同部分。优化结果如下:

以上是benchmark规模
加速器架构

加速器由NFU/stroage/CP三部分组成
NFU
NFU有一下三个特性
· Staggered pipeline
通过流水线提升运行效率
· NFU-3 function implementation
前文中已表示了神经网络中激励函数的实现方式,下文不在赘述
· 16-bit fixed-point arithmetic operators
使用16位定点运算部件
Storage
Q:为什么切分buffer?使用单个多端口buffer似乎更加方便?
A:Concerning Width & Conflicts
拆分结构的第一个好处是将SRAM调整为适当的读/写宽度。
NBin和NBout的宽度均为Tn×2字节,而SB的宽度为Tn×Tn×2字节。
单个读取宽度大小(例如,与高速缓存行大小相同)将是较差的权衡。
如果将其调整为突触,即,如果行大小为Tn×Tn×2,则从Tn×Tn×2宽数据库中读取Tn×2个字节会产生巨大的能量损失,请参见图13,该图表明 对于65nm的TSMC工艺,SRAM读取的能量是存储区宽度的函数。
如果将行大小调整为适合神经元,即,如果行大小为Tn×2,则读取Tn×Tn×2个字节会耗费大量时间。
将存储分为专用结构可以为每个读取请求获得最佳时间和精力。
冲突。
拆分存储结构的第二个好处是避免发生冲突,就像在高速缓存中那样。
由于我们出于成本和能源(泄漏)的原因要使存储结构的尺寸保持较小,这一点尤其重要。
替代解决方案是使用高度关联的缓存。
请考虑以下约束条件:高速缓存行(或端口数量)需要很大(Tn×Tn×2),才能以较高的速率服务于突触; 因为我们希望保持高速缓存的大小很小,所以忍受这么长的高速缓存行的唯一选择是高关联性。
但是,在n路高速缓存中,通过推测性地并行读取所有n路/存储库来实现快速读取。
结果,关联缓存的能量成本迅速增加。
即使是从8路关联的32KB高速缓存中读取64字节,其能耗也比从直接映射的高速缓存中32字节读取65nm的能耗高3.15倍。
使用CACTI进行的测量[40]。
即使仅使用64字节的行,Core i7的第一级32KB数据高速缓存已经是8路关联的,因此我们需要具有很大行的更大关联性(对于Tn = 16,行大小为 512字节长)。
换句话说,在我们的案例中,高度关联的缓存将是昂贵的能源解决方案。
分离存储和对位置行为的精确了解可以完全消除数据冲突。
Exploiting the locality of inputs and synapses
DMAs
Rotating NBin buffer for temporal reuse of input neurons(pooling和conv存在overlap)
Local transpose in NBin for pooling layers
DMA。
对于空间局部性开发,我们实现了三个DMA,每个缓冲区一个(两个负载DMA,一个用于输出的存储DMA)。
DMA请求以指令形式发送给NBin,稍后在第5.3.2节中进行描述。
这些请求被缓冲在与每个缓冲区关联的单独的FIFO中(参见图11),并且在DMA发送了前一条指令的所有存储请求后立即发出这些请求。
这些DMA请求FIFO可以将发出给所有缓冲区和NFU的请求与当前缓冲区和NFU操作解耦。
因此,只要有足够的缓冲区容量,就可以提前预装DMA请求以容忍较长的等待时间。
这种预加载类似于预取,尽管没有推测。
由于NBin(和SB)同时用作重用和预加载缓冲器的暂存器,因此我们使用了双端口SRAM。
台积电(TSMC)65nm库将64项NB的双端口SRAM的读取能量开销估计为24%。
旋转NBin缓冲区,可暂时重用输入神经元。
所有层的输入都分成适合NBin的块,并通过将NBin实现为循环缓冲区来重用它们。
实际上,轮换自然是通过更改寄存器索引来实现的,就像在软件实现中一样,缓冲区条目没有物理(且昂贵)的移动。
NBin中的本地转置用于池化层。
卷积层和池化层之间对于(输入)神经元的数据结构组织存在紧张关系。
如前所述,Kx; Ky通常很小(通常小于10),Ni大约大一个数量级。
因此,将输入要素映射作为三维神经元数据结构的最内层索引,内存提取会更有效(长步1访问)。
然而,这对于合并层是不方便的,因为每个输入特征图仅计算一个输出,即仅使用Kx×Ky数据(而在卷积层中,需要所有Kx×Ky×Ni数据来计算一个输出数据)。
结果,对于池层,逻辑数据结构组织将具有kx; ky作为最里面的尺寸,以便将计算一个输出所需的所有输入连续存储在NBin缓冲区中。
我们通过在NBin中引入映射函数来解决此问题,该函数具有局部转置循环ky的作用; kx和循环i,以便沿循环i加载数据,但将其存储在NBin中,然后沿循环ky发送到NFU; kx首先; 这是通过在加载数据时将数据插入NBin来实现的,请参见图14。
如第3节所述,对于突触和SB,没有重用(分类器层,具有专用内核和池化层的卷积层),也没有在卷积层中重用共享内核。
对于输出和NBout,我们需要重用部分和,即 ,参见图5中的参考sum [n]。这种重用需要在下一节中说明的其他硬件修改。
Exploiting the locality of outputs.
Dedicated registers
Circular buffer (reuse NBout) 绝妙的观察!
是否活跃 NFU-1 NFU-2 NFU-3 POOL √ √ × CONV √ √ if 写入Nbout then 活跃 /if 不写入 Nbout 不活跃 CLASS √ √ if 写入Nbout then 活跃 /if 不写入 Nbout 不活跃
本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。