Tensorflow
TensorFlow的设计思路浅析
问:为什么要了解深度学习框架相关的内容?
目前的大规模深度学习网络往往在异构智能计算系统上运行。
现今采用异构智能计算系统的主要原因:
近十年来通用 CPU 的计算能力增长近乎停滞,而智能计算能力的需求在不断以指数增长,二者形成了剪刀差。例如,寒武纪深度学习处理器能够以比通用 CPU 低一个数量级的能耗,达到 100 倍以上的处理速度。
现阶段的智能计算系统通常是集成CPU和智能芯片的异构系统,软件上通常包括一套面向开发者的智能计算编程环境(包括编程框架和编程语言)。
——《智能计算系统》
目前常用的深度学习编程框架包括 TensorFlow 和 MXNet 等,常用的深度学习编程语言包括 CUDA 语言和 BCL 语言等。 因此,异构系统在提高性能的同时,也带来了编程上的困难。
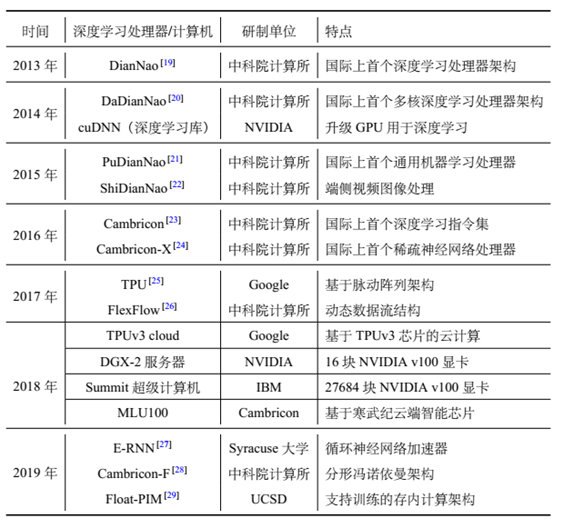
上图为2013年到2019年间深度学习处理器和计算机相关的重大成果统计。我们可以看到,Google不仅实现了Tensorflow,还设计了专用的TPU去支持tensorflow上的硬件加速。他们的贡献应该引起重视。
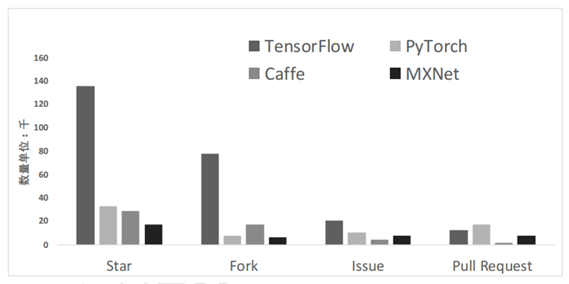
Tensorflow受欢迎的程度可谓一骑绝尘,可以说Tensorflow是当前智能计算系统的编程环境中不可或缺的一环。因此,我们得到一个结论,不论从分布式系统学习的角度、还是从硬件设计的角度;对Tensorflow的了解都是不可或缺的。
从Caffe谈起
Caffe是tensorflow的原形之一,因此我们先来聊一聊Caffe。在前tensorflow时代,caffe几乎是最受欢迎的深度学习框架。

从Caffe论文的引用数量我们就大致能知晓这一框架意义之深远。而事实上,Tensorflow在设计上也深受Caffe的影响。
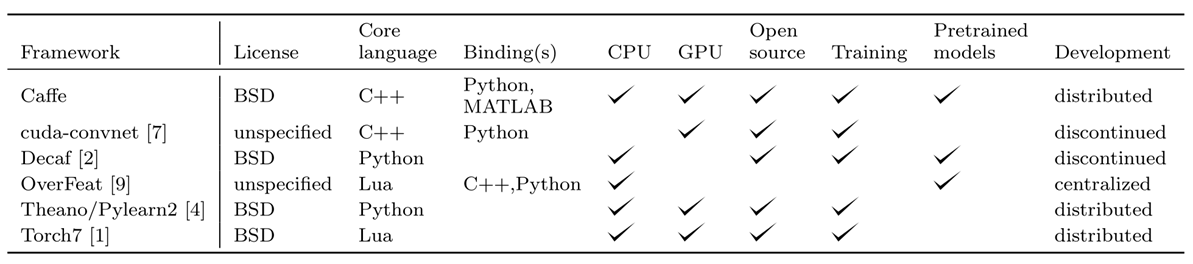
通过上表中的对比可知,Caffe开源,基于c++实现,支持异构计算;对当时的其它深度学习框架可称降维打击。
Caffe的亮点可以归纳如下:
- Modularity. 模块化的设计理念,保证了这一框架的可扩展性
- Test coverage. 每个模块的代码进行充分测试,未经测试的代码不会被合并
- Separation of representation and implementation. 神经网络的结构表示与功能实现分离,用户不必关注底层的实现
- Python and MATLAB bindings. 提供Python和MATLAB支持,在现有的机器学习代码的基础上进行快速原型
- Pre-trained reference models. 提供诸多已预训练的模型(例如 AlexNet),对用户友好
Caffe中的计算图机制也值得一提。在Caffe中,计算以层(Layer)为粒度,对应于神经网络中的层,为每一层给出了前向实现和反向实现。

Caffe固然是一个优秀的框架,但同样存在诸多缺陷:
- 在功能上有很多局限,例如对RNN类的网络支持有限、可部署的设备类型也受限
- 在易用性方面也被Pytorch等主流深度学习框架赶超
- 早期的Caffe版本已经不再维护更新
计算图的两种实现方式
在介绍Tensorflow之前,我们先强调一下计算图的两种主要实现机制——动态图和静态图。而这两种机制差异的本质是编程模式。动态图基于命令式编程,而静态图基于声明式编程
命令式编程:以命令序列的形式来表达程序执行的逻辑

声明式编程:以数据结构的形式来表达程序执行的逻辑
动态图和静态图的区别可归纳如下,
| 名称 | 动态计算图 | 静态计算图 |
|---|---|---|
| 编程模式 | 命令式编程 | 声明式编程 |
| 可调试性 | 容易调试 | 难于调试 |
| 优化程度 | 几乎没有 | 大幅优化 |
| 内存效率 | 低 | 高 |
| 计算效率 | 低 | 高 |
| 循环和控制 | 使用循环和控制命令即可 | 将控制流作为数据结构进行声明 |
Tensorflow的最初版本继承了Caffe的动态图机制,而Pytorch则采用了静态图机制。但两种框架目前都朝着兼容对方的feature的方向发展。
TensorFlow横空出世
Tensorflow 继承了几乎所有Caffe在设计上的优点,改善了Caffe的缺陷。再加上Google的背书,在开源社区和工业界都受到欢迎。
TensorFlow的亮点:
- 性能极佳,充分挖掘了并行能力
- 支持众多常见的前端语言, 覆盖云端到终端几乎所有的平台, 同时也有众多的辅助工具来支持多平台多设备使用
- 社区繁荣, 文档完善, 对初学者友好
TensorFlow的整体架构
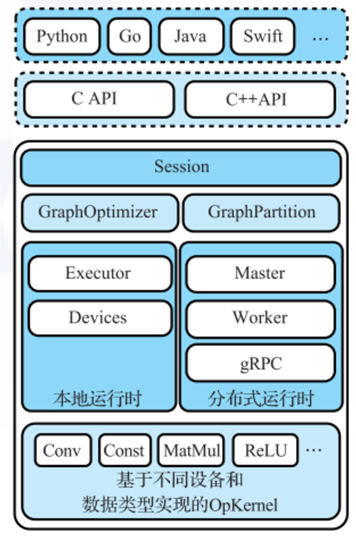
TensorFlow中的主要组件包括:
- 面向各个语言的语言包
提供面向Python,GO等多种语言的支持,方便用户使用
- C/C++ API
基于TensorFlow的核心代码,使用C和C++语言封装了两套API,主要面向有高性能需求的用户
- 后端代码
主要由C++实现的Tensorflow功能后端,保证可移植性和性能
TensorFlow的基本运行流程
关于TensorFlow的运行流程和具体实现这一部分内容非常多。深入讲解与本篇博客的主题偏离的较远,因此这里不再展开。
这里只强调两点:
第一、对于TensorFlow的早期版本而言,只支持静态图的执行。
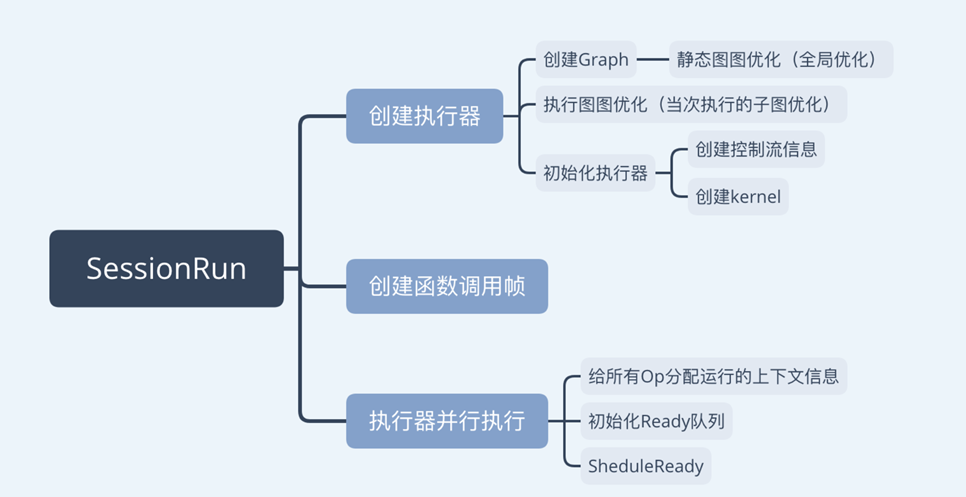
第二、TensorFlow的运行流程可以简要的概括为:用户利用TensorFlow提供的语言包进行声明式编程,定义网络结构。然后语言包通过调用名为Session.run的API将实际的执行交给后端完成。
TensorFlow设计之妙
1.TensorFlow中的计算图设计
TensorFlow中定义了Operation作为计算图结构和功能上的基本单元。 TensorFlow中实现了多种Operation,支持加载输入、进行运算、检查点以及循环控制定义等功能;
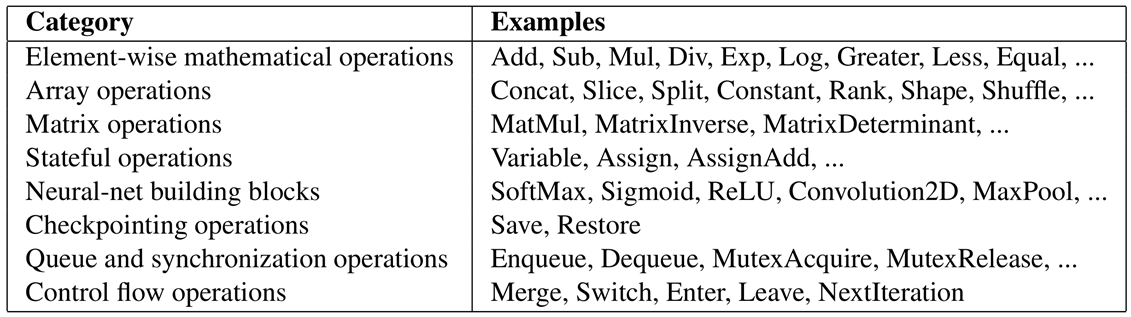
常见的Operation如上图所示。
不同功能的操作在计算图中继承同一基类具备以下优势:
第一、某些公共的方法不必重复去实现,例如设置Operation的名称。
第二、在下文中我们会看到对计算图的全局优化和自动求导等操作都需要在图上进行遍历;当计算图中的各单元都继承相同的基类时,我们的遍历操作更容易实现、也更加安全。
2.计算图的自动求导机制
深度学习网络的执行过程一般可以归纳为三个步骤——第一、前向传播计算loss;第二、反向传播计算梯度;第三、更新参数。
其中梯度计算是整个算法的核心,因此我们介绍Tensorflow中的梯度计算机制。

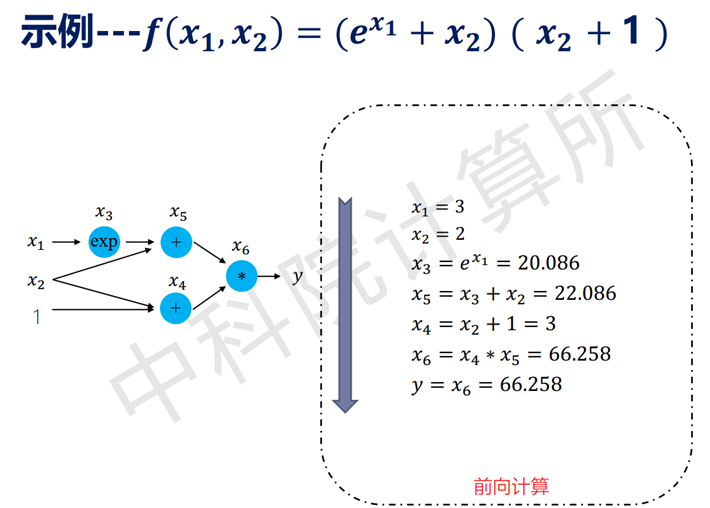
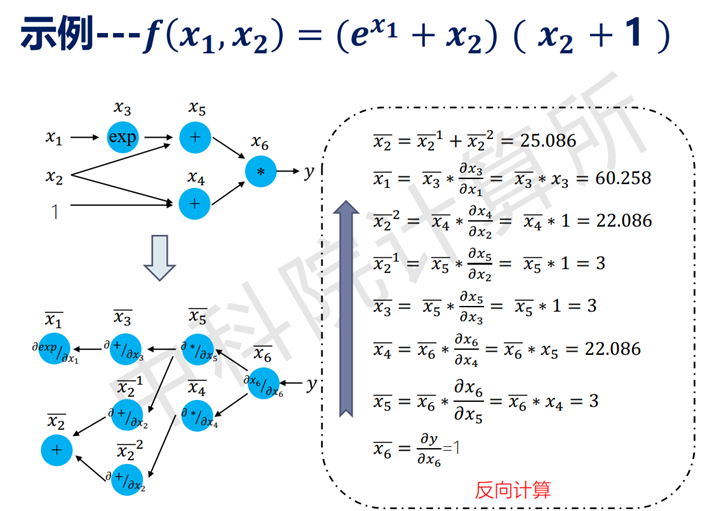
自动求导机制与其他常见求导方式对比如下:
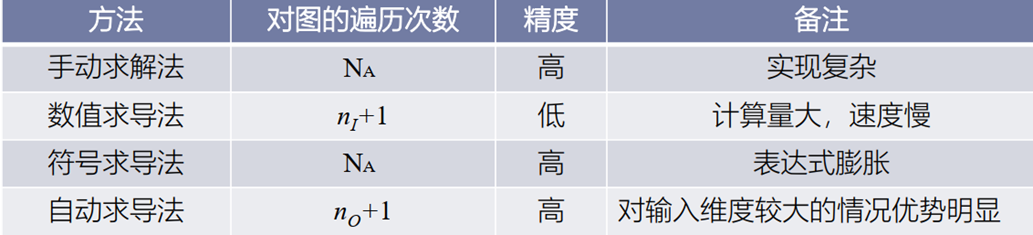
该求导方式的优点可归纳如下:
灵活,框架可以完全向用户隐藏求导过程。用户只需描述前向计算的过程, 由编程框架自动推导反向计算图, 完成导数计算
只对基本函数运用符号求导法, 因此可以灵活结合编程语言的循环结构、条件结构等进行求导
3.计算图的执行模式
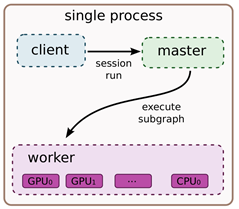
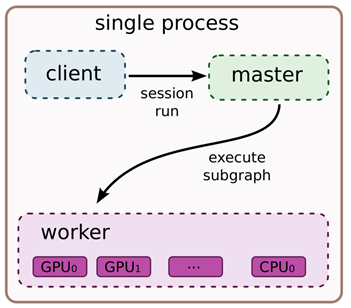
计算图的本地执行模式中有如下要件:
- client:通过session接口与master和worker通信
- master:控制所有的worker按照计算图执行
- worker:每一个worker负责一个或多个计算设备的仲裁访问,并根据master的指令,执行这些计算设备中的计算图
- 设备:CPU、GPU、TPU和其他类型的加速器,此外TensorFlow支持自定义设备的注册
首先考虑最简单的执行场景: 一个worker进程中仅包含一个设备的情况。 在该情况下:
一、 计算图按照节点(对应计算图中的Operation)之间的依赖关系顺序执行 二、每个节点有一个计数器, 记录其依赖节点中尚未执行的节点数量, 一个节点执行完成, 则其所有依赖节点的计数器计数递减
三、当计数器计数为0时, 则该节点可以执行, 并将其添加到就绪队列中
当本地存在多个可用设备时,计算图需经过一系列处理后分配到各设备上运行。
处理流程总结如下:
计算图剪枝

计算图分配

计算图优化
TensorFlow中的图优化由Grappler模块来实现
通过图优化, 可以根据不同的硬件结构调整计算调度策略, 从 而获得更快的计算速度和更高的硬件利用率 也能减少推断过程中所需的峰值内存, 从而运行更大的模型
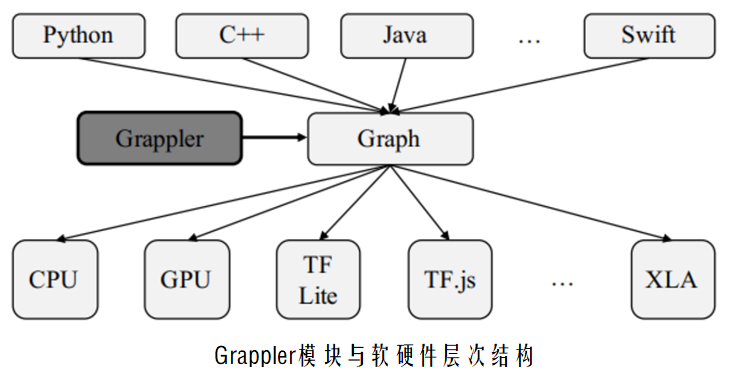
在TensorFlow中计算图优化的常见技术如下:


计算图切分
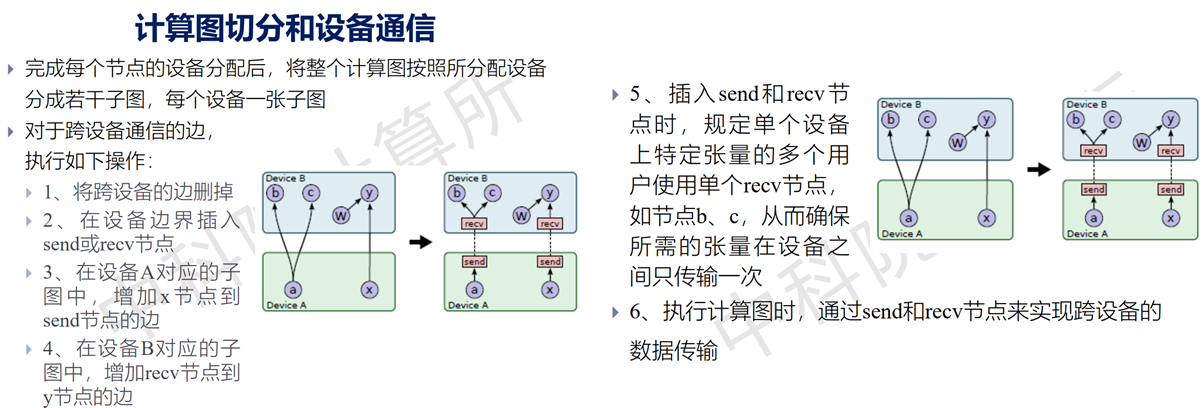
这里有一个需要注意的点:本地多设备执行其实和分布式执行的机制是相同的;send和recv在本地通过总线或者NV-LINK协议实现数据传输,在分布式的情况下,往往通过TCP或者RDMA保证数据的可靠传输。Google的架构师通过这种方式实现了本地执行和分布式执行的统一化,在笔者看来十分优雅。
4.TensorFlow增加同步并行效率的设计技巧
TensorFlow中的并行方式包含以下几种:
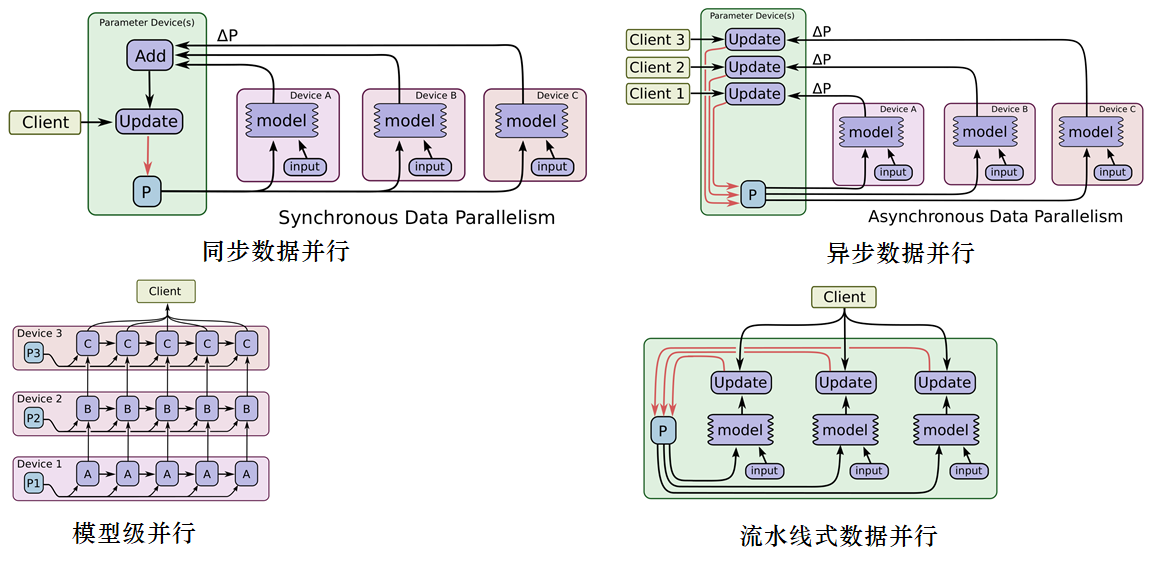
同步数据并行策略的吞吐量相对于异步数据并行策略小,但是往往有更快的收敛速度。Tensorflow 采用了一种特殊的方式,通过增加冗余资源来保证同步数据并行能达到近似异步数据并行的效率。
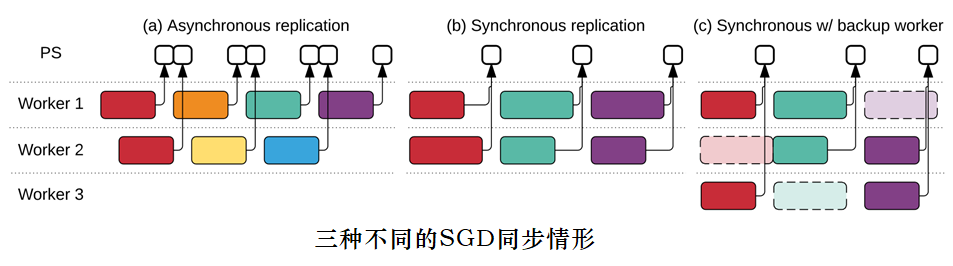
1、在异步情况(a)下,每个worker在步骤开始时读取参数,并将梯度异步地更新到参数并应用到自身——确保了高吞吐率,但各worker中常使用过时的参数,不是非常有效。
2、同步情况使用队列协调执行:将阻塞队列作为Barrier,以确保所有worker读取相同的参数,另一个队列收集多个梯度更新,并以原子方式应用参数。(b)情形下总吞吐量受限制。
3、为了解决较低效率的worke造成的瓶颈,实现了备份worker如所示(c),这与MapReduce的备份任务机制类似。 系统周期性检测是否存在落后woker – 若存在、则备份worker主动运行,聚集将采用3个更新中的前2个。
该技术对于吞吐量和加速比的提升非常明显,下图为Google的实验结果。

这个设计技巧虽然简单粗暴,但是十分有效。通过增加少许计算资源突破瓶颈;是一种值得学习的设计思路。
本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。